Beyond Transformers: Exploring Mixture-of-Recursions (MoR), the Next Step in AI
Looking Back: The Transformer Revolution
In 2017, Google DeepMind unveiled the revolutionary Transformer architecture in the now-iconic "Attention is All You Need" paper. Like many in the AI community, I remember my early experiments vividly—I used transfer learning with Transformers to classify images of my friends. The results were astonishing, even on that small, personal dataset.
That breakthrough changed everything. Transformers quickly became the backbone for countless advances in artificial intelligence, powering state-of-the-art language models and making the democratization of AI a reality. Every major large language model released since then—whether for text, images, or multi-modal tasks—has stood on the shoulders of this architecture.
Enter Mixture-of-Recursions (MoR): The Next Frontier
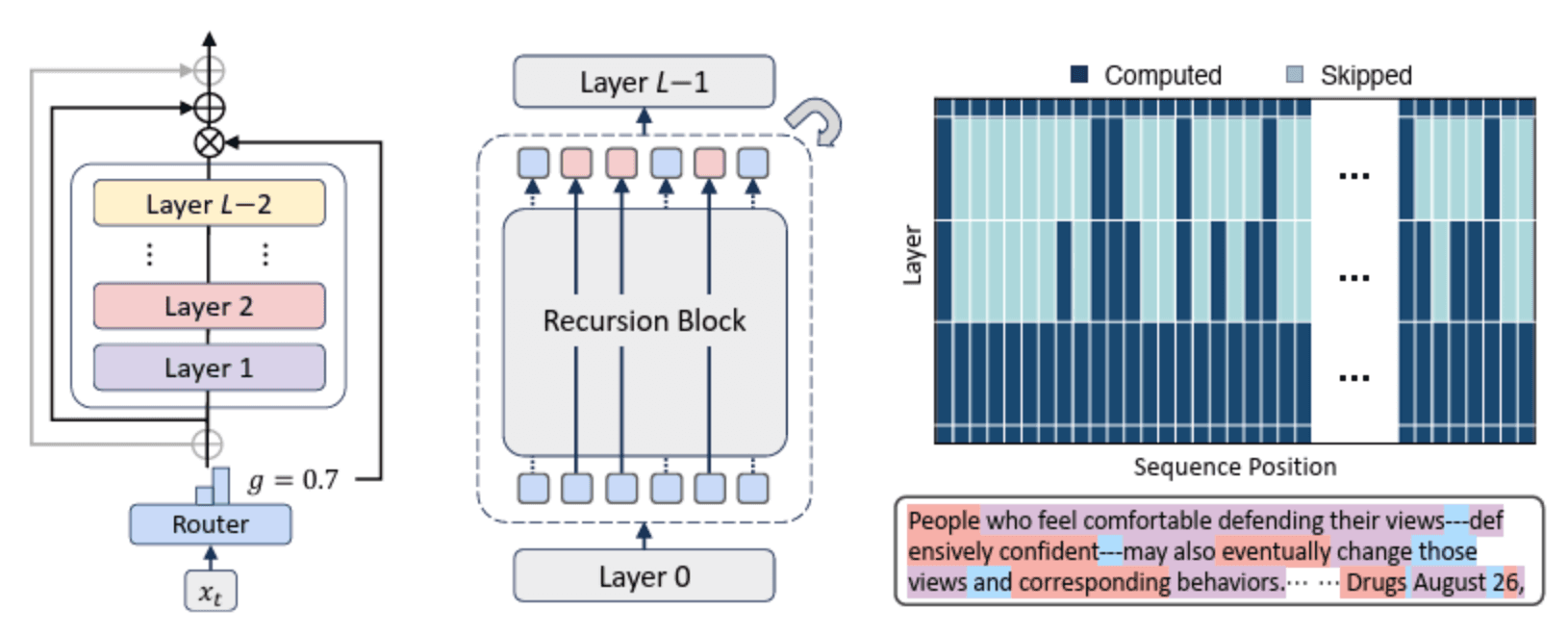
But now, the landscape is shifting again. The introduction of Mixture-of-Recursions (MoR) offers a compelling solution to a fundamental challenge in large language models: how to allocate computational resources—dynamically and efficiently—based on the specific demands of each input token. As the paper discusses here are some highlights:
Game-Changing Efficiency
Training time reduction: up to 19%.
Peak memory usage: 25% less, compared to standard Transformers.
Model size: can be halved (a 50% reduction) with comparable quality.
Adaptive per-token inference cost: making computation smartly distributed.
With MoR, you get similar—or even better—accuracy at much lower cost, using less memory and compute. Imagine deploying powerful AI models on edge devices or in enterprise settings with strict hardware constraints. Suddenly, things like real-time translation or advanced on-device assistants become much more feasible.
How Does MoR Differ from Transformers?
At its core, MoR extends transformer-based models by introducing a recursive processing mechanism per token:
Adaptive Computation: Each token’s embedding passes through a recurrent computation block, where the number of steps is determined “on the fly” for each token.
Flexible Routing: An attention-like gating mechanism decides, for every token, how much computation it actually needs.
Preserving Training Power: All routing decisions remain differentiable, so the entire model can be trained end-to-end with gradient-based methods.
In traditional Transformers, every token, regardless of simplicity or complexity, is processed identically through each layer. MoR changes the game: the depth of computation per token adapts based on context and difficulty, so easy tokens pass quickly, while hard tokens get more attention. It’s as if each word in a sentence gets the exact amount of consideration it deserves—no more, no less.
Implications and Applications
Language Models: Faster, cheaper inference for straightforward inputs—full horsepower for nuanced, tricky parts.
Resource-Constrained Environments: MoR is perfect for mobile, IoT, and edge devices where saving every millisecond (and every megabyte of RAM) counts.
Interpretability: The recursion depth of tokens offers a visible indicator of which parts of text the model finds most challenging or important.
Why This Matters
Scaling language models isn't just about adding more GPUs or bigger clusters. It's about efficiency—using computational resources where they're needed most. Mixture-of-Recursions marks a leap toward truly adaptive, resource-savvy AI systems, with huge implications for everything from cloud-based translation services to personal, privacy-focused AI assistants running right on your device.
With each wave of innovation, AI becomes more accessible, more powerful, and more energy-efficient. MoR could very well be the architecture that defines the next era of AI—just as Transformers did eight years ago.
Head on to the git page to delve into more deeply: https://github.com/raymin0223/mixture_of_recursions
